Why ultra-short TTLs don't work (the way you expect)
We run the hostmaster service for a large automotive OEM, managing roughly 50,000 DNS records. In that environment, we regularly get requests to set DNS records with very short TTLs — sometimes 60 seconds, sometimes even 5 seconds, or with no TTL at all. The reason given to us is usually the same: if the IP changes, everyone should instantly see the new address.
It sounds logical, but in practice it just doesn't work that way.
DNS is a multi-layered system — authoritative servers, recursive resolvers, client caches, and sometimes even application caches — and each of those layers can behave differently. DNS was designed in the 1980s. Expecting a system that old, with that many independent layers, to behave this agile is just not realistic.
That's why, at our scale, we don't accept TTLs lower than 3600 seconds anymore, and for NS sets the standard is 86400. That may sound "long," but it reflects how DNS actually works, not how people wish it would work.
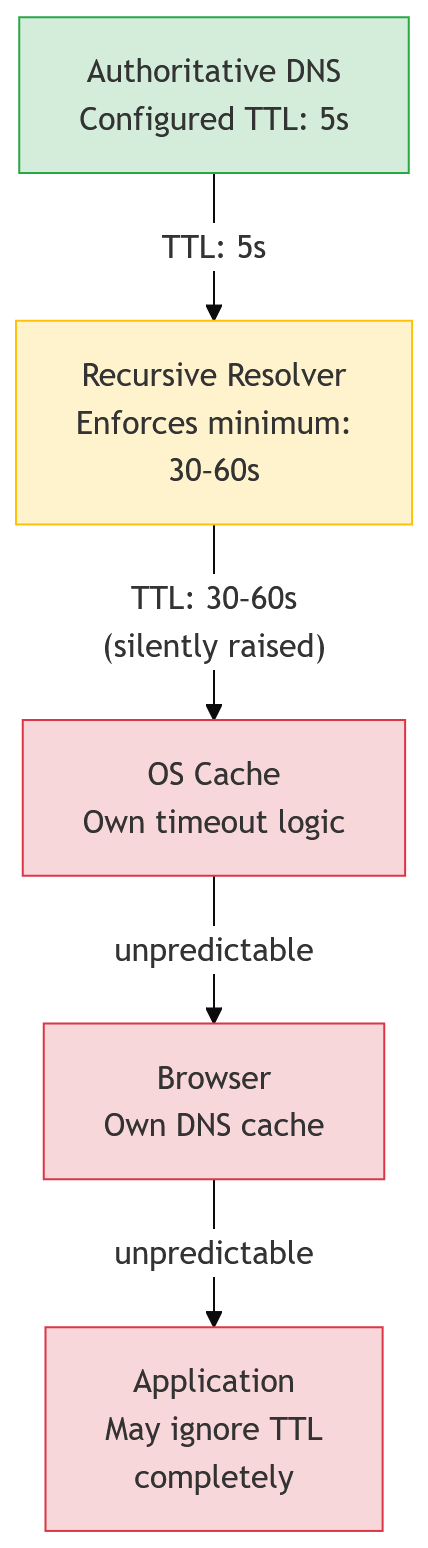
The Expectation vs. The Reality
- Expectation: Have a 5-second TTL, and when you change the IP, all clients worldwide will immediately get the new IP.
- Reality:
- Many resolvers enforce their own minimum caching time, so your 5 seconds may become 30, 60, or more.
- Clients (browsers, operating systems, applications) often cache far longer — or ignore TTLs entirely.
- The processes for actually updating DNS entries are rarely fast enough to make such short TTLs useful.
- Ultra-short TTLs just make the clients hammer DNS infrastructure without solving the real problem.
In short: short TTLs create expectations that DNS simply isn't designed to fulfill.
Why they don't work
On paper, a TTL of 5 or 60 seconds sounds like a good thing: change the IP in the DNS record, and the clients out there see the change near-instantaneously. In reality, there are several hard limitations that make such settings ineffective or even counterproductive.
Resolver Minimums
Many recursive resolvers apply their own minimum caching time. If you configure a record with a 5-second TTL, it may be silently raised to 30 or 60 seconds — sometimes even more. The result: the ultra-short TTL never actually takes effect outside of your own server.
Client-Side Caching
Even if a resolver respects your low TTL, the client may not. Browsers, operating systems, and applications often cache DNS responses independently, sometimes for minutes or hours, regardless of what the authoritative TTL says. This means end users can still end up resolving the "old" IP for a long time.
Application Behavior
Some applications implement their own DNS logic entirely. In those cases, no TTL setting — short or long — will change the client's behavior.
Infrastructure Strain
Every query that bypasses caching needs to hit the next DNS layer, most often up to your server. With tens of thousands of records, setting very short TTLs multiplies the query volume dramatically. That just hammers your DNS infrastructure for no benefit.
Cloud-based DNS services also regularly bill by the million (or billion) of DNS requests they process. So setting the TTL this low doesn't just create load — it can create significant cost, without any consistent upside.
Inconsistent behavior
Here you might wonder: on the one hand, low TTLs don't improve propagation. On the other hand, they cause more load. How can both be true?
The answer is simple: client implementations are inconsistent. Some will re-query constantly, others won't bother at all. The supposed benefit of a low TTL — fast global propagation — is unreliable at best. And since you always have to plan for the "or not" case anyway, the low TTL buys you nothing except more noise.
In short: low TTLs don't guarantee faster propagation, but they do guarantee more load and complexity.
A Common Request: Route 53 and 60-Second NS Sets
One request we see again and again is when someone wants to delegate a zone to AWS Route 53 and insists that the NS records should have a TTL of 60 seconds.
On the surface, it might sound like a smart way to "stay flexible." In reality, it makes no sense. NS sets almost never change, and when they do, it's as part of a carefully planned migration. There is zero benefit to refreshing them every minute.
What actually happens is that resolvers all over the world keep asking for the same NS set again and again, hammering DNS infrastructure for no reason. The expectation is that a low TTL improves agility; the reality is that it just wastes resources without delivering any faster propagation.
It's a textbook case where intention (faster updates) and outcome (higher load, same delays) are completely misaligned.
A note on Route 53: This isn't a critique of Route 53 as a DNS service — it's reliable, well-operated, and a reasonable choice for many use cases. It just can accrue large cost for zones which have a high number of queries on them. But like any platform, it comes with defaults and patterns that deserve scrutiny. Accepting a suggested configuration without understanding why is where things go wrong, regardless of which provider you're using.

How to do it right
If the goal is smooth cutovers or minimizing downtime, the answer isn't to permanently set ultra-low TTLs. It's to plan and use TTLs strategically.
Use Realistic Defaults
For day-to-day operation, TTLs in the range of 3600 seconds (one hour) are perfectly fine. For NS records, up to 86400 seconds (one day) can be right. These values give stability and predictability without unnecessary load.
Lower TTLs Temporarily
If you know a migration or cutover is coming, lower the TTL on the relevant records ahead of time (for example, from 3600 to 300 a day or two before). Once the change is done, raise the TTL back to a stable value.
The truth is: most clients do respect a short TTL — but not all, and you always have to plan for those that don't.
Plan, Don't Wing It
DNS cutovers succeed because of preparation, not because of a magic number in a TTL field. Staging, dual setups, and clear communication avoid far more downtime than a 5-second TTL ever could.
Plan for overlap
Any cutover will always have clients still hitting the old infrastructure while others already use the new one.
If that's unacceptable, don't rely on DNS at all to handle the transition. Use a load balancer or similar mechanism that gives you a controlled cutover moment. Those tools are deterministic. DNS isn't.
Conclusion
Short TTLs are often requested with the best intentions — but they don't deliver what people hope for. DNS is not a real-time system: resolvers impose minimums, clients cache on their own terms, and applications sometimes ignore TTLs completely.
What short TTLs do deliver is extra load on DNS infrastructure and sometimes even extra cost. What they don't deliver is faster or more reliable propagation.
The better approach is to set realistic defaults, plan ahead for cutovers, and use TTL adjustments as a temporary tool when needed. With the right preparation, DNS can be stable and adaptable — without chasing the myth of real-time updates.